News
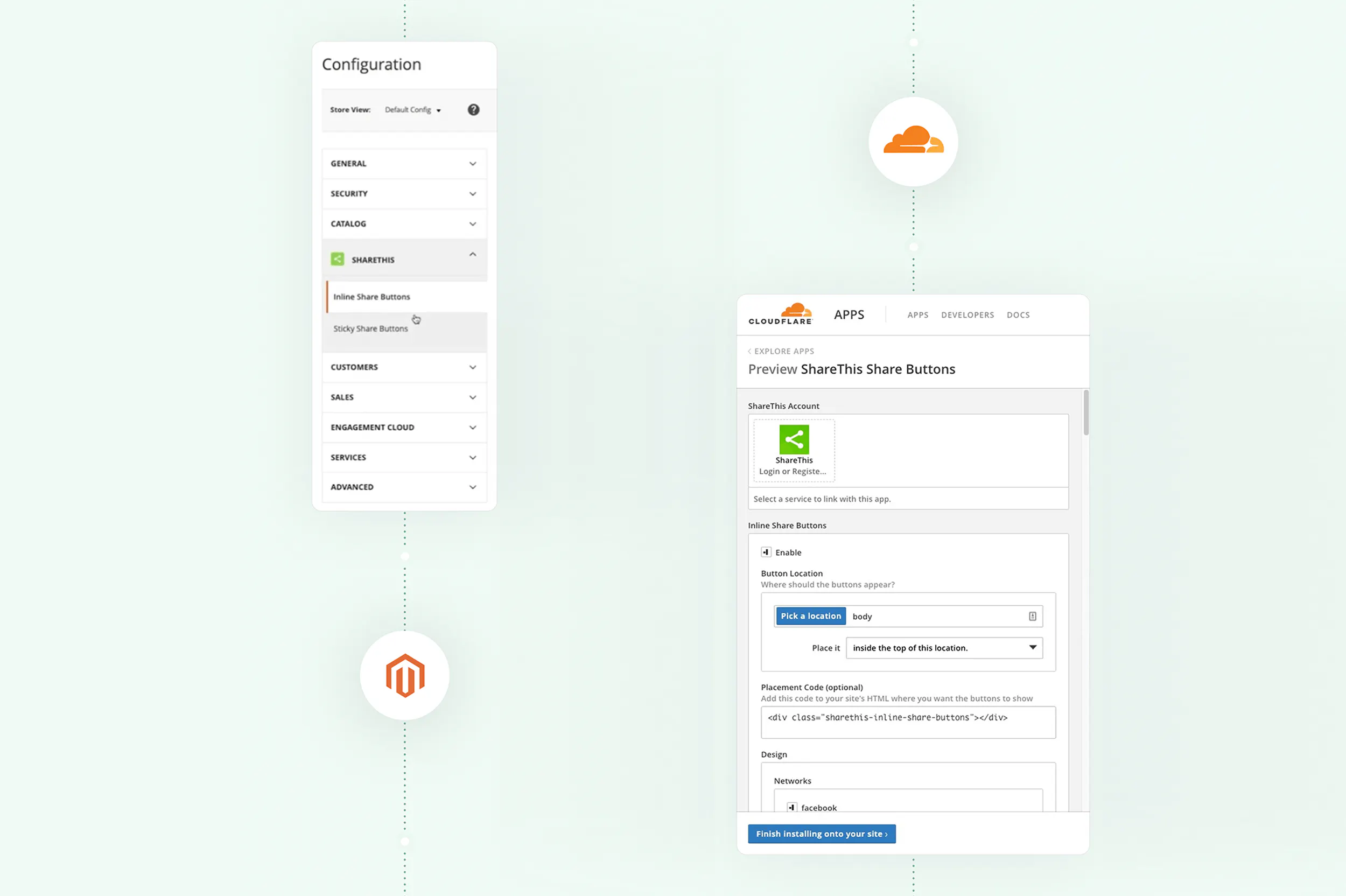
ShareThis Delivers on the Promise of Cookieless Data Solutions
As Google moves forward with plans to discontinue support for third-party cookies by the end of 2024 (pending approval from the UK Competition and Markets Authority), there is no doubt that this will...
3m read